
お世話になっております。
以下表題の件にて。
スクレイピングデータ
行数で315000行
38391レース。
であっている。・・・はず。
課題
- 選手の力をデータに反映する
- 計算量を抑えるために、不必要なデータを持たない
- 競輪無知識なので、データから見て、気になった点を調べて、ドメイン知識を得る。
- データの正確性、集計数値があっているか確認する
集計数値があっているか確認
はじめて競輪公式サイトを見る。
手元データから、選手をランダムに選び、集計数値があっているか調べる。
平均競走得点遷移グラフが役立つと認識した。
見比べる
デグレンデルさんという選手名が目に入る。
そこで検索すると、ニッキー デグレンデルさんが出てくる。
きっとこの方だと思われる。
この方を、公式サイトで成績を見てみる。
手元データ
手元データで、2.0=常に最低2着までに入っているはずだ。
※驚異的な数字で不安になる。
コード
print(df[df['選手名'] == 'デグレンデル']) [13 rows x 38 columns]
データの重複はないはずだが、13レコードある。
13レース以上、通算成績で2着以内になっているはず。
実際の通算成績
| 総出走回数 | 出走数 | 優勝 | 1着 | 2着 | 3着 | 着外 | 棄権 | 失格 | 勝率 | 2連対率 | 3連対率 | |
| ~1昨年 | ||||||||||||
| 昨年 | 合計 | 13 | 4 | 12 | 1 | 0 | 0 | 0 | 0 | 92.3% | 100.0% | 100.0% |
合っている。
というか、すごい選手だ。
分散
着順がどんな状況でもバラけない。
分散しない人が強いという仮説を作って検証してみる。
※これは計算しやすい
着順の分散
着順がどんな状況でもバラけない。
分散しない人が強いという仮説を作って検証してみる。
対象の選手
前回、グレンデルさんという選手を先に調べている。
ここでは、ウェブスターさんを比較対象に選んだ。
ウェブスターさん
6.173280
グレンデルさん
0.076923
これが分散。
agg([‘var’])で出している。
0に近いほどバラけない=成績が安定している。
着順が下位でも安定しているなら、外れ値を出さないタイプということでいいと考えた。
その結果、ここの分散が高いと、オッズや予想を覆して勝つのかもしれないと思い始める。
分散が高い人にフラグを立てておいて、外れ値=大穴値を作れるかもしれないという素人考え。
公式のデータと比較
予想 ウェブスターさんは、勝ったり負けたりしているはず。
| 総出走回数 | 出走数 | 優勝 | 1着 | 2着 | 3着 | 着外 | 棄権 | 失格 | 勝率 | 2連対率 | 3連対率 | |
| ~1昨年 | 合計 | 21 | 1 | 11 | 4 | 1 | 5 | 0 | 0 | 52.3% | 71.4% | 76.1% |
| F1 | 21 | 1 | 11 | 4 | 1 | 5 | 0 | 0 | 52.3% | 71.4% | 76.1% | |
| 昨年 | 合計 | 19 | 4 | 14 | 1 | 2 | 2 | 0 | 0 | 73.6% | 78.9% | 89.4% |
| F2 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 100.0% | 100.0% | 100.0% | |
| F1 | 18 | 3 | 13 | 1 | 2 | 2 | 0 | 0 | 72.2% | 77.7% | 88.8% | |
一昨年の着外が分散を作っているようだ。
そこで、年単位の成績で特徴量を作ることにする。
またついでに月単位、週単位などで、予測したい日の前日より前のデータを、特徴量に反映するようにしたい。
重要な指標はなんだ
着順に関連する指標で、ざーっとデータを見てみると、Kドリームスの予想印通りに買うのが一番当たる。
当たるが外れるパターンもあって、それを可視化、定量化する。
不明な点「競走得点とレース番号」
競走得点と呼ばれるものと、第何レースか、というものの関連性が見える。
現時点では、競走得点というものの算出ルールを知らないが、レースにたくさん出ていると、増えるものなのかもしれない。
こう考えると、競走得点が増える→レースにたくさん出られるいい選手→勝つというような想像をしてしまう。
これは今後、しっかり調べる。
不明な点「車番」
もしかしてこの数値が重要というのは、内枠外枠での着順への影響があるということ?
これは従来の競輪予想サイトさんを見れば、すぐ調べがつくと予想。
強い世代
これは研究初期に気づいた。
なんだかやたら強い黄金世代みたいな人たち。
モーニング娘。さんの何期はすごかったみたいなことが、競輪世界にもあると予想。
2019/12/19追記
本紙予想は「◎○×△▲注」
デスク予想は「◎○×△▲」の順で強弱が表現されます。
◎印
◎がついたKドリームスの予想と、自身の機械学習での予測値が1着であった場合、36レース中21レースが的中。
確率64%
未熟な機械学習モデルでこの結果。
予測:1着or2着or3着、結果:1着or2着or3着内に入ったレース数は26レースある。
○印
○がついたKドリームスの予想と、自身の機械学習での予測値が2着であった場合、36レース中8レースが的中。
確率23%
ここでだいぶ確率がバラけてくる。
予測:2着、結果:1着or3着だったケースが+2レース。
予測:1着、結果:1着が1レース
予測:1着、結果:2着が2レース
予測:1着、結果:3着が3レース
予測:3着、結果:5着6着7着が1レースずつ。
連対率は悪くないという印象。
※この時点で2値分類での正解率は楽しみに取っておくことにしている。
予測:1着or2着or3着、結果:1着or2着or3着内に入ったレース数は16レース。
×印
×がついたKドリームスの予想と、自身の機械学習での予測値が3着であった場合、36レース中0レースが的中。
確率0%
これがたまにTweetさせていただいている、3着が当たらないんだという話。
しかし、予測:1着or2着or3着、結果:1着or2着or3着内に入ったレース数は10レース。
確率28%
ここまでとここから
ここまでは、レース単位では見ていない。
あくまで印+実際の着順:予測。
ここからは実際にどうなると当たるのか。
的中するのか。

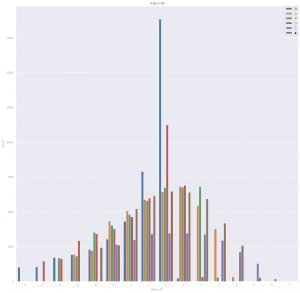
このグラフは、予想印に対して、右に行くと成績良。
左に行くと成績悪。
◎の青線は、0が多い。
◎=1は1着になるはずなので、その場合は1-1で差が0。
だから◎は0が多い=そのまま1着になった数も多い。



予想印からそのまま買うと外れてしまうのですね。
本命の◎は信用できるかと思います。
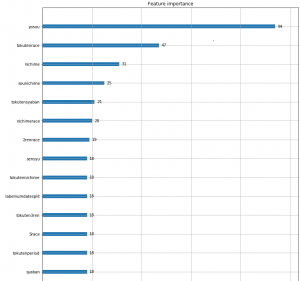
重要度の可視化
予想印が重要というのは体感していたものの、定量的に見ると、他の列の倍。 競走得点というものを全く知らないので、競走得点が、なぜ予想に起因するのか調べる必要がある。 なるほど、競走得点とは、出場レースのグレードによる成績の数値なんですね。 ※調べてきました。 直近4ヶ月ということは、弊社予想システムも、4ヶ月より過去のデータを反映しないか、4ヶ月毎に区切って学習するのもいいかもしれない。
重要度の画像
相関係数の画像
準備中
現在の正解率(kerasの2値分類)
tp, fn, fp, tn = confusion_matrix(test_y, Y_pred).ravel() print(cm) print(tp, fn, fp, tn) from sklearn.metrics import recall_score recall_score(test_y, Y_pred) [[194 16] [ 44 28]] 194 16 44 28 0.3888888888888889 from sklearn.metrics import f1_score f1_score(test_y, Y_pred) 0.4827586206896552
これがkerasの2値分類の結果です。 keras+2class 結果は、F値がもっと高かったら良かったのだけれど、これ単体ではあまり使い物にならないという印象。
現在の正解率(Lightgbmの2値分類)
tp, fn, fp, tn = confusion_matrix(test_y, y_pred).ravel() print(cm) print(tp, fn, fp, tn) from sklearn.metrics import recall_score recall_score(test_y, y_pred) [[197 13] [ 45 27]] 197 13 45 27 0.375 from sklearn.metrics import f1_score f1_score(test_y, y_pred) 0.4821428571428572
これがLightgbmの2値分類の結果です。 keras+Lightgbm
2019/10/31の福井競輪を買っていたらどうなっていたのかを検証
FCTV杯 けーぶるちゃん。賞 ※なんだこの賞の名前は???
検証 2019年10月31日 1レース
予測:1着@2番 山中 崇弘選手(以下各選手敬称略) 結果:6着 予測:1着@3番 奥原 亨(ほぼ同確率で1着予測) 結果:1着 予測:2着@4番 植田 誠 結果:2着 予測:3着@7番 兵動 秀治 結果:5着
想定する買い方
(2-3)に絡めて4と7の組み合わせを買うことを第一想定。 2車連複 3連勝複 というのを買うことを第二に想定する。 そうなると、 2-3 2-4 2-7 3-4 3-7。
上記の研究から、
◎がついたKドリームスの予想と、自身の機械学習での予測値が1着であった場合、36レース中21レースが的中。 確率64%
そのため、もともとの予想印の◎=3番を軸にすることになる。 2-3 3-4 3-7 2-3-4 2-3-7 3-4-7 くらいが車券の購入候補。 ※ただ、1着予測が2個と、現在の予測に不審な点があるため、そもそも購入しないという選択肢を取りそうではある。
支出と収入
これで100円で6点購入したとして、600円支出。 3=4:380円 だけ当たるので、380円の収入。 このままだとまずいぞ。
傾向と対策
予想印の確度を確かめられる機械学習モデルになっている気がする。 他のレースを見ても、予想印と予測がシンクロしてしまっている。 その予想印と反する結果が出た時は、予測も的中していないが、予測着順が予測印に対してバラけるため、本命対抗以外の何かが起こるのは、予測から読み解ける状態。 その他、予想印と予測が一致している場合、3連勝複式までは当たるが、単式はダメ。 この未熟な機械学習モデルでも、買い方を考えることで、それなりにはやれそうだが…。
?
いや、3着が当たらないということは??? そもそも3着が当たらないという原因は、3連勝複を意識した構成がモデル内にあるせいもある。 そこで、1,2着を当てるモデルと、全着順を当てるモデルに分割することにしました。 Lightgbm keras XGBoost にてそれぞれを作ることにしました。
k近傍法での予測
正確に3着内の予測が立つものが少ない。 36レース中、述べ25選手を3着内予測。 うち、21個が的中。 レース単位で見てみると、2車連複で購入できるものが6レース。 ※これはなんのことかというと、ある1レースに3着内の予測が2個以上ある場合、買うということ。 1レース外れているので、5レース的中。 的中確率83%
3連勝複
2レースフラグが立って、1レース当たり。 外れたもう1レースは、2車連複当たり。 的中確率50% 2019年11月02日 11レースは、もともとカチカチ予測で、それが的中。 外れた方は10レースで、本命対抗はカチカチ予測で、1着2着は的中だが、複数車券を買っていると僅かに収入がマイナスになる。
2020/01/07追記
結局、どのモデルも1,2着の正解確率が78%程度になってきました。 これはこれでいいとして、当たるパターンというか、それを可視化したものを公開します。
当サイトはリンクフリーです。
ご自身のブログでの引用、TwitterやFacebook、Instagram、Pinterestなどで当サイトの記事URLを共有していただくのは、むしろありがたいことです。
事前連絡や事後の連絡も不要ですが、ご連絡いただければ弊社も貴社のコンテンツを紹介させていただく可能性がございます。
